[Big Data] Deploy a Apache Flink session cluster natively on Kubernetes (K8S)
Apache Flink — Stateful Computations over Data Streams
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
Here, we explain Flink’s architecture.
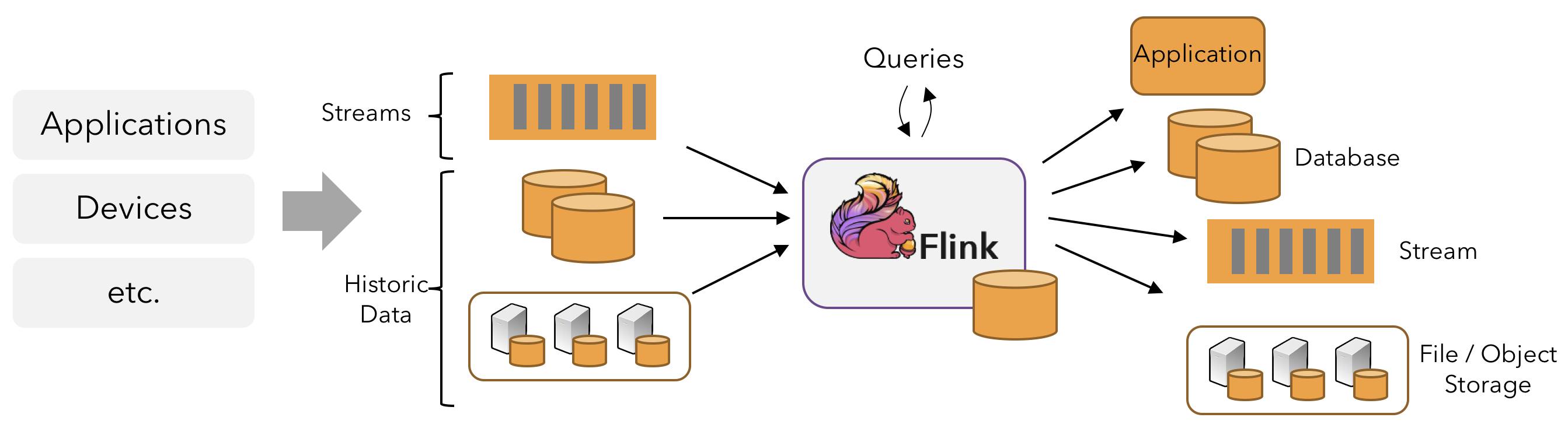
This article describes how to deploy a Flink session cluster natively on Kubernetes.
Flink’s native Kubernetes integration is still experimental. There may be changes in the configuration and CLI flags in latter versions.
Prerequisites
-
Java
To be able to run Flink, the only requirement is to have a working Java 8 or 11 installation. You can check the correct installation of Java by issuing the following command:
1
2
3
4
5CentOS
java-11-openjdk
yum install java-11-openjdk
java -version -
Kubernetes (K8s) is an open-source system for automating deployment, scaling, and management of containerized applications.
For more information about installing and using Kubernetes (K8s), see the Kubernetes (K8s) Docs.
-
kubectl
The Kubernetes command-line tool, kubectl, allows you to run commands against Kubernetes clusters. You can use kubectl to deploy applications, inspect and manage cluster resources, and view logs. Install and Set Up kubectl | Kubernetes - https://kubernetes.io/docs/tasks/tools/install-kubectl/.
Installation
Download
To be able to run Flink, the first step is to download Apache Flink: Downloads - https://flink.apache.org/downloads.html.
1 | tar -xzf flink-1.11.2-bin-scala_2.11.tgz |
You can relace 2.11 with your prefer Flink version.
Start Flink Session
Follow these instructions to start a Flink Session within your Kubernetes cluster.
A session will start all required Flink services (JobManager and TaskManagers) so that you can submit programs to the cluster. Note that you can run multiple programs per session.
You can relace cloudolife-example-flink-cluster-id and cloudolife-example-namespace with your prefer values.
Create an Namespace.
1 | kubectl create namespace cloudolife-example-namespace |
Install Flink Kubernetes (K8S) session.
1 | ./bin/kubernetes-session.sh \ |
See Pods
1 | kubectl get pods -n cloudolife-example-namespace |
Submitting jobs to an existing Session
Use the following command to submit a Flink Job to the Kubernetes cluster.
1 | ./bin/flink run -d -t kubernetes-session -Dkubernetes.cluster-id=cloudolife-example-flink-cluster-id -Dkubernetes.namespace=cloudolife-example-namespace examples/streaming/WindowJoin.jar |
See Pods
1 | kubectl get pods -n cloudolife-example-namespace |
Configuration
All the Kubernetes configuration options can be found in Apache Flink 1.11 Documentation: Configuration - Kubernetes - https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/config.html#kubernetes.
The follow may be the commmon configuration options.
| Key | Default | Type | Description |
|---|---|---|---|
| kubernetes.cluster-id | (none) | String | The cluster-id, which should be no more than 45 characters, is used for identifying a unique Flink cluster. If not set, the client will automatically generate it with a random ID. |
| kubernetes.config.file | (none) | String | The kubernetes config file will be used to create the client. The default is located at ~/.kube/config |
| kubernetes.container.image | The default value depends on the actually running version. In general it looks like “flink:<FLINK_VERSION>-scala_<SCALA_VERSION>” | String | Image to use for Flink containers. The specified image must be based upon the same Apache Flink and Scala versions as used by the application. Visit https://hub.docker.com/_/flink?tab=tags for the images provided by the Flink project. |
| kubernetes.namespace | “default” | String | The namespace that will be used for running the jobmanager and taskmanager pods. |
Uninstallation
#TODO
1 |
References
[2] Apache Flink: Stateful Computations over Data Streams - https://flink.apache.org/
[3] Apache Flink: Downloads - https://flink.apache.org/downloads.html
[5] Kubernetes - https://kubernetes.io/
[6] Install and Set Up kubectl | Kubernetes - https://kubernetes.io/docs/tasks/tools/install-kubectl/